General Workflow
Our application workflow takes input as a file and after that our program converts it to XML and process it to represent data on the terminal Interface




EPub
In case of ePub, we have used ePub Python Library to get content from the epub file after which our application makes the Class Structure to handle and manipulate various aspects of a document





PDF


After that, we have information of the various content files present in an ePub document. These files have meta-structure in form of XML and content in form of HTML, for post-processing of these HTML we used Beautiful Soup Library and converted texts into navigable blocks.

For the navigation purpose, we made another class Structure which handles all the navigation requests and respond accordingly.

And hence our output comes straight to the terminal Interface as

In PDF we have used PDFMINER library to get the data from the pdf file and convert the data into the XML format.We have made various functions to handle different requests.
For example this the header content search function it is called when the user wants to search some specific data within the header.
 This is the list of all the headers in the document and can be printed on demand of the user.
This is the list of all the headers in the document and can be printed on demand of the user.
 Search function to search any particular heading, paragraph or word in the whole text.
Search function to search any particular heading, paragraph or word in the whole text.
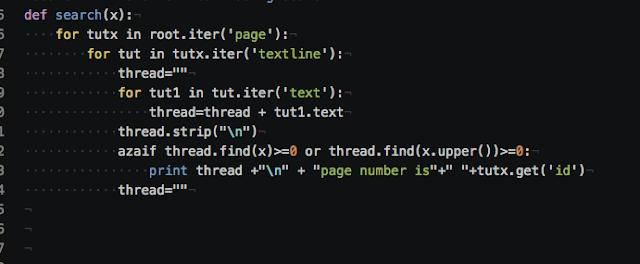



Output to the terminal interface is same as Epub file output.So with the help of these function and libraries, we execute the PDF part.
Daisy books
For daisy files, firstly we had to unzip the daisy resource folder using the python unzip library. We have parsed the whole XML file as an element tree using python XML.elementTree library. And then to get contents out of the XML content file, we have again used python beautiful soup library.

This allows us to parse large documents efficiently & fast. We have included various navigation functions in the file like previous/next page/para/header, going to a specific page/para/header, searching and replacing text, printing table of contents etc.

Also, we have done paragraph wise parsing of content because RBD device has only storage memory up to 50-100 MB.
